Deep learning on point clouds plays a vital role in a wide range of applications such as autonomous driving and AR/VR. These applications interact with people in real time on edge devices and thus require low latency and low energy. Compared to projecting the point cloud to 2D space, directly processing 3D point cloud yields higher accuracy and lower #MACs. However, the extremely sparse nature of point cloud poses challenges to hardware acceleration. For example, we need to explicitly determine the nonzero outputs and search for the nonzero neighbors (mapping operation), which is unsupported in existing accelerators. Furthermore, explicit gather and scatter of sparse features are required, resulting in large data movement overhead. In this paper, we comprehensively analyze the performance bottleneck of modern point cloud networks on CPU/GPU/TPU. To address the challenges, we then present PointAcc, a novel point cloud deep learning accelerator. PointAcc maps diverse mapping operations onto one versatile ranking-based kernel, streams the sparse computation with configurable caching, and temporally fuses consecutive dense layers to reduce the memory footprint. Evaluated on 8 point cloud models across 4 applications, PointAcc achieves 3.7X speedup and 22X energy savings over RTX 2080Ti GPU. Codesigned with light-weight neural networks, PointAcc rivals the prior accelerator Mesorasi by 100X speedup with 9.1% higher accuracy running segmentation on the S3DIS dataset. PointAcc paves the way for efficient point cloud recognition.
Point cloud has become a very important and popular modality in our daily life with a wide range of applications, including augmented reality and autonomous driving. These applications require real-time interactions with humans, and thus it is crucial to emphasize not only high accuracy but also low latency and low energy consumption.

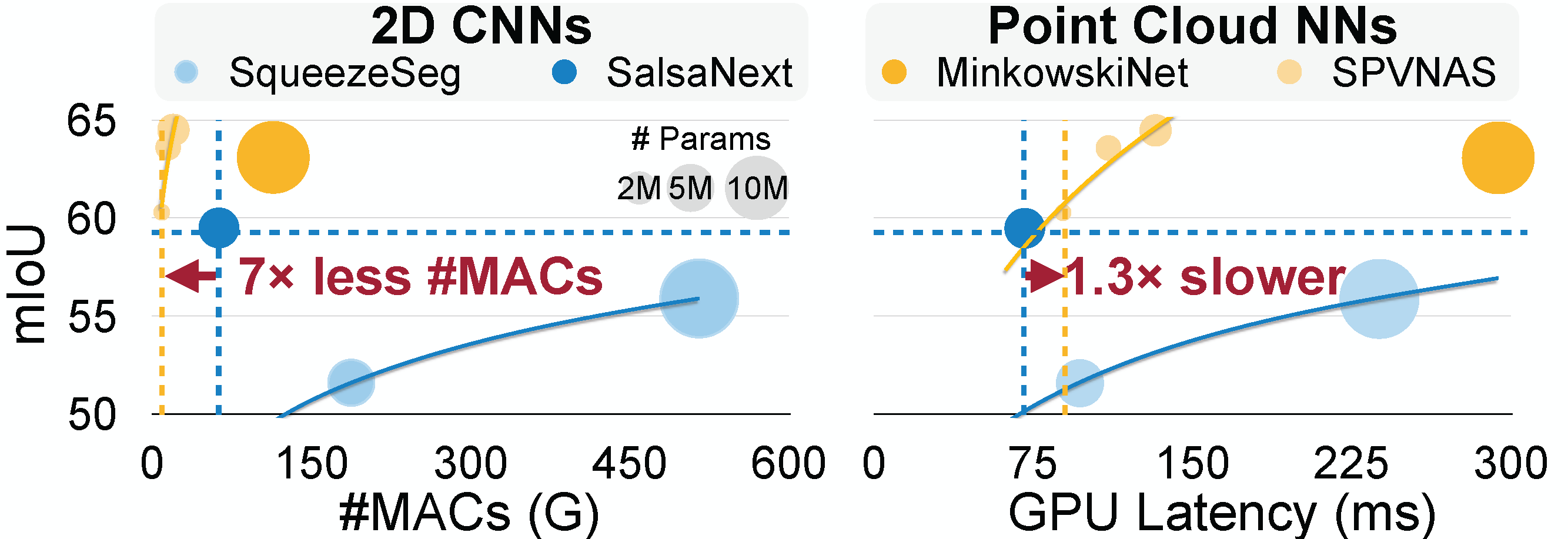
Compared to projecting 3D point cloud to 2D then applying Convolution Neural Networks (CNN) on 2D flattened point clouds, directly processing 3D point clouds with Point Cloud Networks yields up to 5% higher accuracy with 7X less #MACs. However, point cloud networks run significantly slower on existing general-purpose hardware than CNNs. The state-of-the-art point cloud model MinkowskiUNet (114G MACs) runs at only 11.7 FPS even on a powerful NVIDIA RTX 2080Ti GPU, while ResNet50 (4GMACs) with similar input size can run at 840 FPS.
Unlike the inputs of image CNNs which are dense tensors, point clouds are naturally sparse: e.g., outdoor LiDAR point clouds usually have a density of less than 0.01%.

Moreover, the sparsity in point clouds is fundamentally different from that in traditional CNNs which comes from the weight pruning and ReLU activation function. The sparsity patterns of point clouds are constrained by the physical objects in the real world. That is to say, the nonzero points will never dilate during the computation.

Therefore, point cloud processing requires a variety of mapping operations, such as ball query and kernel mapping, to establish the relationship between input and output points for computation, which has not been explored by existing deep learning accelerators. Moreover, strictly restricted sparsity pattern in point cloud networks leads to irregular sparse computation pattern. Thus it requires explicit gather and scatter of point features for matrix computation, which results in a massive memory footprint.

Due to extreme sparsity, mapping operations and data movement overhead together take up >50% of the total runtime latency. What's worse, due to unsupported mapping ops, data movement between co-processors (CPU and TPU) worsens the bottleneck.

We present PointAcc architecture design: Memory Management Unit bridges the other two units by preparing the data for Matrix Unit based on the output of Mapping Unit. By configuring the data flow in each unit, PointAcc flexibly supports various point cloud networks efficiently.

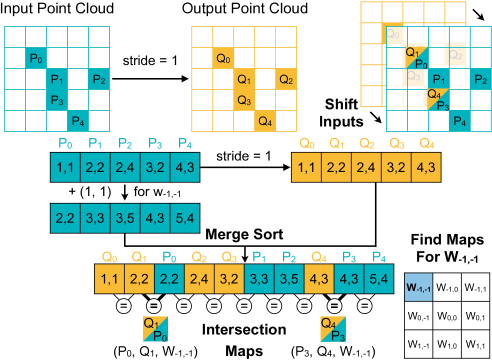
The ultimate goal of mapping operations is to generate maps in the form of (input point index, output point index, weight index) tuple for further computation (e.g., convolution). We observe that no matter which algorithm is used, these maps are always constructed based on the comparison among distances. Thus we offer to convert these comparisons into ranking operations, and process in parallel for different points in the point cloud (point-level parallelism).

The following figure shows an example of searching for (input, output) pair of weight w(-1, -1). It is converted into a coordinates intersection, and implemented with parallelizable merge-sort operation.
PointAcc sequentially fetches input features on demand in the granularity of tile (i.e., "cache block"). Matrix multiplication computing parallelizes input and output channels dimension, so that there is no need for on-chip scatter network. PointAcc opts weight stationary for inner loop nests to reduce on-chip memory accesses for weights, and opts output stationary for outer loop nests to eliminate the off-chip scatter of partial sums. PointAcc further configures the Input Buffers as a direct-mapped cache to reduce the #off-chip read of reused data to nearly 1 access.

Layer fusion helps to reduce the off-chip memory access of these intermediate activations. However, conventional spatial layer fusion has complication logic overhead, restricts the usage of intermediate buffers and fixes the number of layers for fusion. Since the number of consecutive dense layers varies among different point cloud networks and even among the different convolution blocks in the same model, PointAcc exploits the temporal layer fusion, which only requires simple logic modification, and supports flexible buffer use for better layer tiling and flexible number of fused layers.

Performance Gain of the full version PointAcc over server-level products:

Performance Gain of the edge version PointAcc over edge-level devices:


On CPU and GPU, our merge-sort-based conversion for kernel mapping operation actually worsens the performance. It is because of excessive off-chip memory access of intermediate datain the merge sort, and doubled point cloud size during the post-processing. However, PointAcc spatially pipelines the stages of merge sort and intersection detection, the overhead is cancelled.Furthermore, PointAcc runs 1.4X faster running kernel mapping over hash-table-based ASIC implementation, and 1.18X faster running k-nearest-neighbor over quick-sort-based TopK Engine in previous work. Using one versatile architecture outperforms specialized design for each mapping operation independently.

On GPU, fetching only the on-demanded input features saves the data movement cost by 3X. Though, the matrix-matrix multiplication is thus decomposed into matrix-vector multiplication, which significantly increase the computation overhead due to the low utilization of GPU cores. However, such overhead is removed in PointAcc because of the computation power of the systolic array.

On the left shows the probability density of DRAM footprint per layer in MinkowskiUNet. A wider region indicates higher frequency of the given data size. The shape of distribution are nearly the same with/without caching, which indicates that the caching works consistently on different layers and on different datasets. On average, the configurable cache reduces the layer DRAM access by 3.5X to 6.3X, where each point features are only fetched nearly once on average.On the right shows the reduction ratio of DRAM access when running PointNet++-based networks with layer fusion. Compared against running networks layer by layer independently, our layer fusion help cut the DRAM access from 33% to 41%.

@inproceedings{ lin2021pointacc,
title={{PointAcc: Efficient Point Cloud Accelerator}},
author={Lin, Yujun and Zhang, Zhekai and Tang, Haotian and Wang, Hanrui and Han, Song},
booktitle={54th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO ’21),},
year={2021}
}
This work was supported by National Science Foundation, Hyundai, Qualcomm and MIT-IBM Watson AI Lab. We also thank AWS Ma- chine Learning Research Awards for the computational resource.



